
L’Active Learning, une stratégie efficace pour diminuer le coût et le temps du travail préparatoire de vos données.
Pas d'intelligence artificielle sans données.
S’il est un aphorisme connu dans le domaine de l’intelligence artificielle, c’est bien celui-là !
Comme le résume à la perfection le graphique ci-dessous, près de 75% du temps alloué à un projet de Machine Learning concerne le rassemblement et la manipulation des données brutes ; celles qui serviront à entrainer votre modèle avant sa mise en production.
Que ce soit dans la reconnaissance d’images, l’analyse prédictive, le classement de documents ou l’extraction de métadonnées, vous devrez toujours en amont fournir un set d’apprentissage (training set).
Dans les projets les plus fréquents d’apprentissage supervisé (Surpervised Learning), ce set de données comprend un ensemble plus ou moins important de couples « données – résultats ». En effet, pour travailler efficacement, votre modèle a besoin de s’inspirer de cas réels dont il connait déjà… les réponses !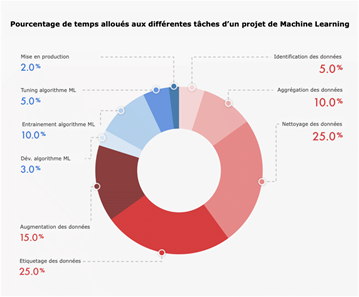
L’étiquetage, frein courant à la mise en place d’un projet d’intelligence artificielle
Si vous avez choisi de construire un algorithme prédictif qui automatise un traitement particulier, c’est vraisemblablement parce que le coût du calcul de cette prédiction (le classement, l’extraction de données particulières, l’identification d’objets sur une image, …) est élevé en temps et/ou en argent.
Pour démarrer votre projet, vous aurez cependant besoin d’enrichir les données du set d’apprentissage au cours d’un processus qui s’appelle l’étiquetage.
Cette phase, qui doit forcément impliquer des collaborateurs humains, est un frein courant à la mise en place d’un projet. Soit parce que l’étiquetage est coûteux, dangereux, long ou nécessite des opérateurs qualifiés peu disponibles.
Réduire l’impact de l’étiquetage grâce à l’Active Learning
Il convient donc de minimiser au maximum le nombre de données à étiqueter : c’est ce qu’une stratégie d’Active Learning vise avant tout.L’Active Learning ou Cooperative Learning consiste à filtrer, au long d’itérations successives, les données les plus pertinentes à faire annoter par un opérateur humain. Chaque set d’annotations est consolidé avec les précédents pour reconstruire un modèle qui sera lui-même utilisé pour affiner la sélection de nouvelles données à étiqueter.
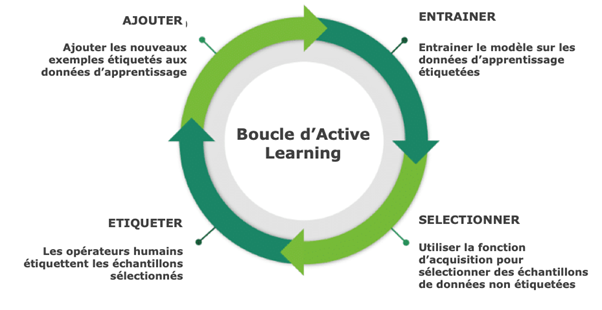
Les études montrent un gain qui s’étend de 20% à 80% de données qui ne devront donc pas être étiquetées. En outre, un modèle construit sur un set d’entrainement sélectionné à partir d’une stratégie d’Active Learning peut largement dépasser les performances d’un modèle construit sur un set plus classique.
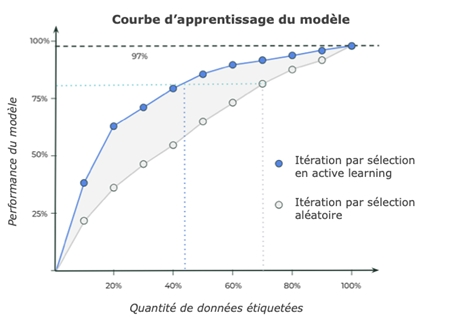
L’exemple ci-dessus montre qu’il faut 70% de données étiquetées pour atteindre 80% de performance. Alors qu’avec une stratégie d’Active Learning, la quantité est inférieure à 50%.
Le gain est significatif !
Le Laboratoire IA de NSI
Dans le cadre de nos projets de classification d’images et de traitement de documents en vue d’archivage automatisé ou d’extraction de métadonnées, nous mettons systématiquement en place une stratégie de ce type.
La préparation et le traitement de vos données constituent une étape primordiale qui se révèle très souvent être la clé de réussite de votre projet d’intelligence artificielle !


